Пока страшных регулярок нет, все достаточно просто выглядит. Действовал так:
-
По умолчанию для каждой ноды elastic’а разрешено создание IngestNode, но можно повесить такую обработку и на другую ноду, которая будет заниматься только предобработкой поступающих данных. У меня пока все на одной ноде. Инфа по настройке здесь: https://www.elastic.co/guide/en/elasticsearch/reference/5.1/ingest.html
-
Для IngestNode нужно предварительно загрузить pipeline в котором описать processors для предобработки данных. Начать можно с такого описания:
PUT _ingest/pipeline/onec_pipeline
{
“description” : “onec pipeline”,
“processors” : [
{
“grok” : {
“field”: “message”,
“patterns”: [
“%{INT}:%{BASE10NUM}-%{INT},%{WORD:event}”
]
}
}
]
}
Здесь, по сути делаю следующее: по регулярке “%{INT}:%{BASE10NUM}-%{INT},%{WORD:event}” определяю событие ТЖ, которое помещается в поле event индекса, а поиск идет по полю message. Понятно, что написание регулярки можно продолжить и вытащить остальные поля, такие как описание, текст запроса, план запроса. Для поиска таких записей применяем, например: Descr=%{QS:ИмяПоляИндексаДляХраненияОписанияСобытияТЖ}.
- Дополнительные поля для индекса задаю в шаблоне индекса, который находится в настройках filebeat (/etc/filebeat/template.json). Например, так добавил поле event:
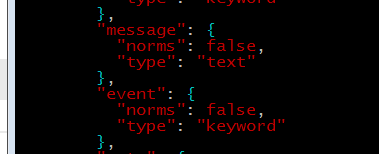
в поле message хранится строка лога ТЖ. Можно добавить и другие поля, в которые с помощью processor’а добавлять другие события.
- В настройках filebeat (/etc/filebeat/filebeat.yml) сделал следующее:
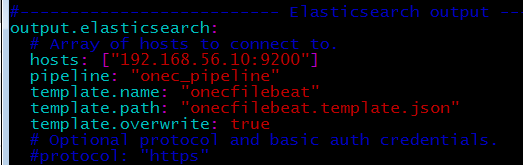
Явно прописал предобработку данных по pipeline и свой шаблон индекса.
Еще нужно добавить в настройки filebeat обработку многострочных записей, делается так:
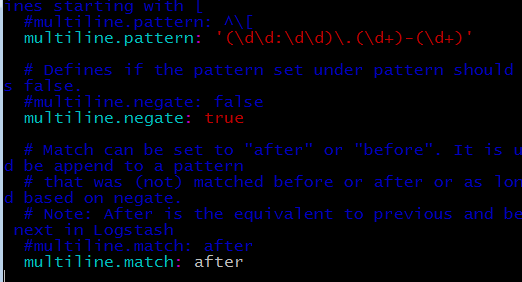
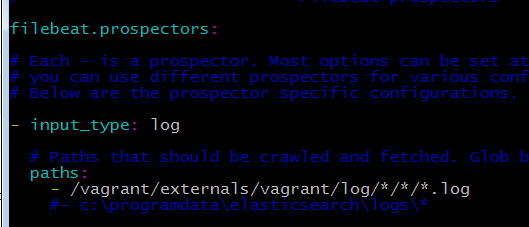
Для сбора логов в настройке filebeat указал:
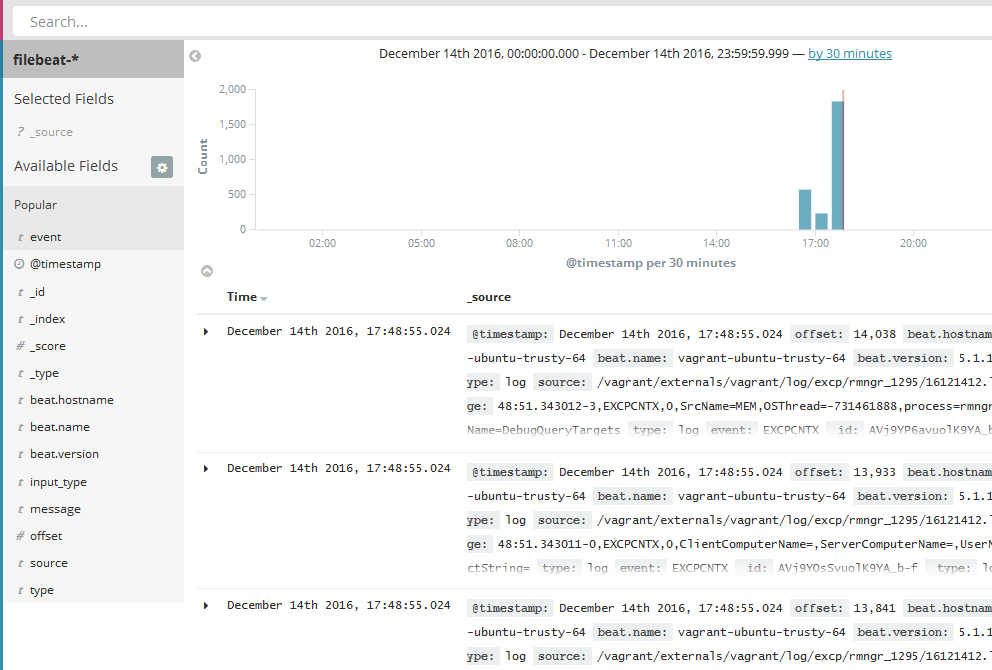
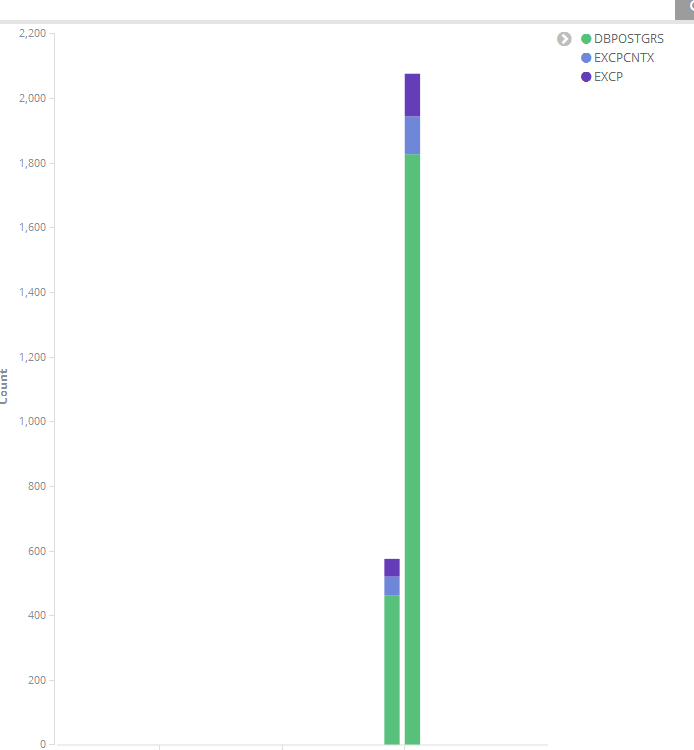
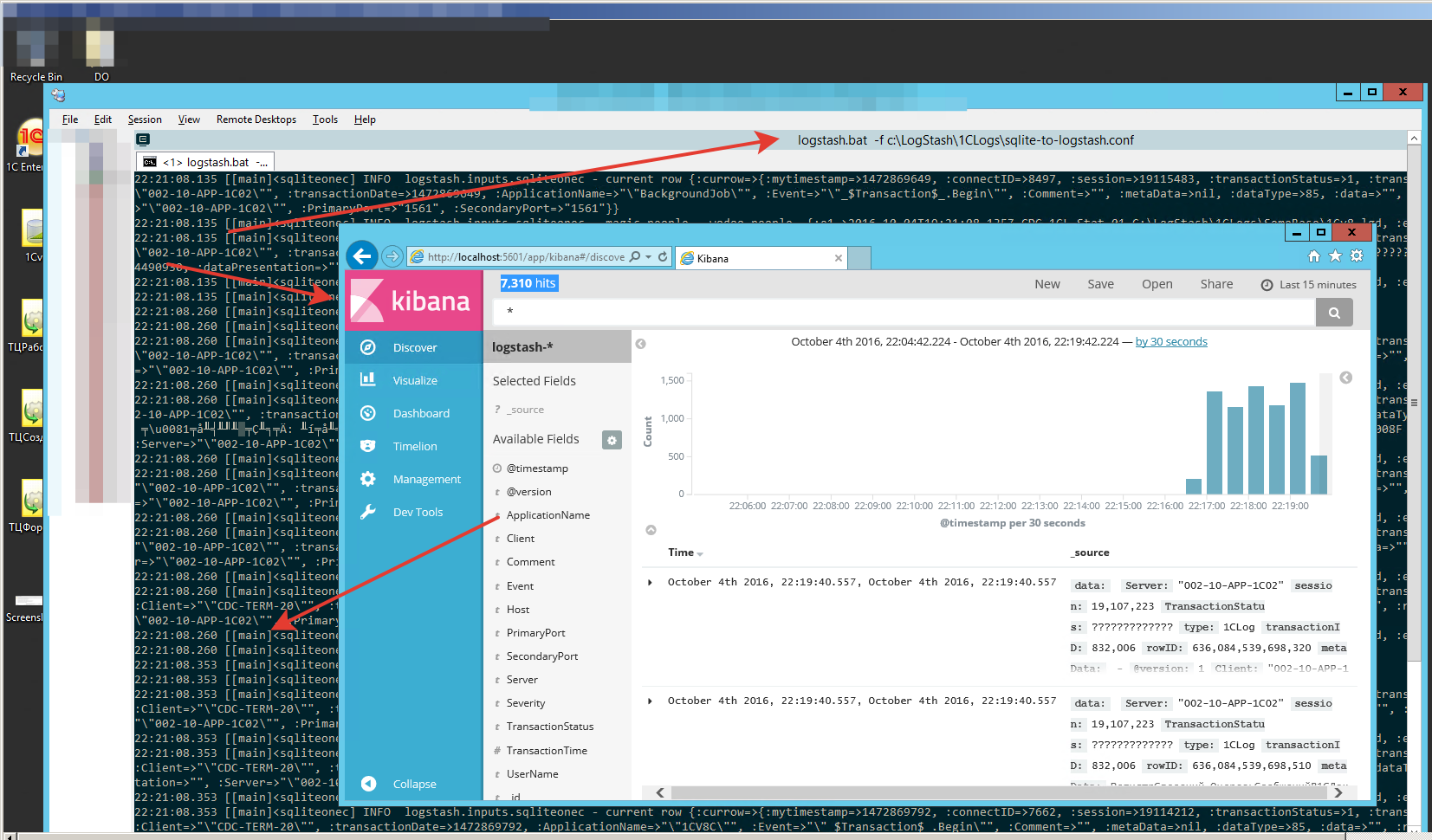
Стартуем elastic и filebeat, смотрим в kibana результат.


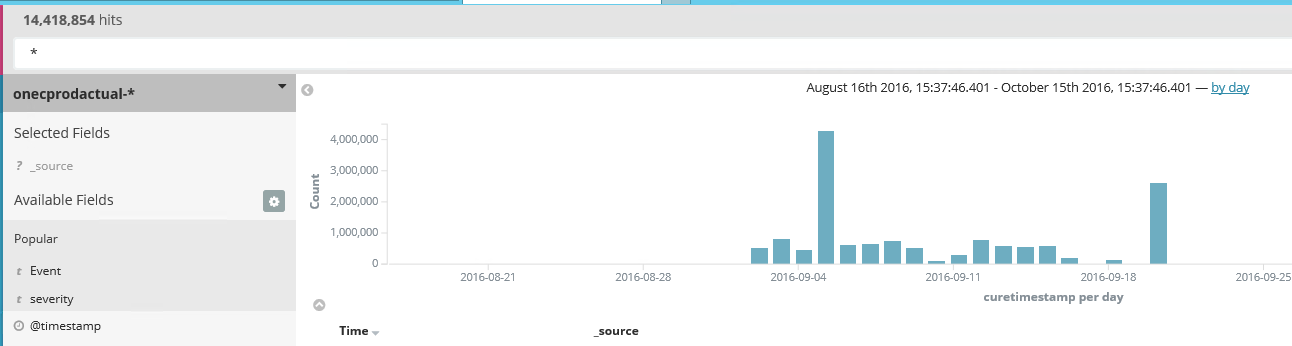
 с прошлого воскресенья. где-то 45 гигабайт журналов. Но это я явно накосячил со слипами
с прошлого воскресенья. где-то 45 гигабайт журналов. Но это я явно накосячил со слипами