
@pumbaE, обычная обработка 1С для запуска из командной строки. Тестирую по OS X и Windows, предполагаю, что и под Linux будет работать, но пока не могу определенно сказать.
BigData LogManager для 1С
Ок, тогда думаю можно и на oscript будет портировать. Тогда как на github опубликуете, добавлю туда и очистку старых индексов, т.е. ежедневный индекс удалить, а добавить ежемесячный для старых данных, тогда не будет деградации производительности у эластика.
Репозиторий:
Оно все еще требует доработки, в текущем виде пригодно разве что - для ознакомления.
Важный момент, чтобы Kibana работала - ИспользованиеByteOrderMark.НеИспользовать
Приглашаю в issues для обсуждения 
1 Симпатия
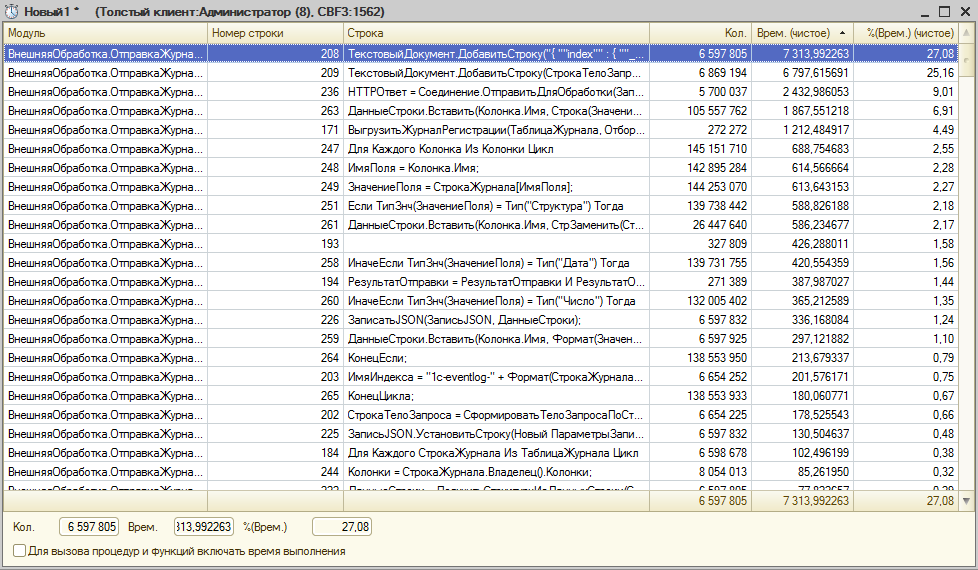
Если кто тестил обработку - мог заметить - самым узким местом была отправка запросов к ES. У меня это было 20000 за 600 сек.
Я подумал, что это непозволительно долго и переписал это дело на _bulk API (https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html)
Теперь 70% времени тратится на строку:
СтрокаЗапрос = СтрокаЗапрос + "{ ""index"" : { ""_index"" : """ + ИмяИндекса + """, ""_type"" : """ + ИмяТипа + """ } }" + Символы.ПС;
Как думаете, есть способы оптимизации?
Говорят, ТекстовыйДокумент складывает строки намного быстрее. Из-за использования какого-то другого буфера.
Итак, что происходит при выполнении операции S=S+“Some Text”
Происходит т.н. ReAlloc (перевыделение памяти):
a) Выделяется область памяти размером = размер(S) + размер(“Some Text”)
b) В выделенную область копируется S
c) В выделенную область дописывается "Some Text"
d) Адрес дескриптора строки S устанавливается на новую область
e) Старая область памяти, использовавшаяся S освобождается
Спасибо большое! Текстовый документ действительно ощутимо быстрее.
Теперь новые вводные 150_000 записей не пролазят одним запросом, почему то. Еще разбираюсь с этим.
Если там http запросы, может попробовать multipart через boundary?
Получил забавную ситуацию:
После загрузки в ES ~5_000_000 записей на виртуалке под docker-machine закончилось свободное место в результате индекс за 1 месяц оказался разрушен с полной потерей данных  при этом сервер продолжал принимать запросы и отвечал на запись новых с кодом 200, как ни в чем не бывало.
при этом сервер продолжал принимать запросы и отвечал на запись новых с кодом 200, как ни в чем не бывало.
То что 150_000 не пролазило решил разделением на порции по 50_000
Короче говоря, О сколько нам открытий чудных готовит просвященья дух. (с)
Замер производительности (запущен не с самого начала)
Без тестов ? Без feature файлов ? Как так можно. Ну хоть бы заглушку создал для фич.
1 Симпатия
Я с самым первым вопросом застрял “Mock в привязке к 1С” - чем сэмулировать ES?
Докером, без хранения данных.
Контекст:
Дано: Вызвана команда docker up elk
Сценарий Выгрузка данных
Хозяйке на заметку - самый быстрый способ потоковой записи текста - это
ЗаписьXML.ЗаписатьБезОбработки(ВашТекст);
быстрее ЗаписьТекста и уж тем более ТекстовогоДокумента.
3 Симпатий
Добрый день.
Решаю задачу разбора логов ТЖ 1С и их анализа средствами ELK.
Архитектура следующая:
Сервер 1. На нем: Служба 1С, FileBeat.
Сервер 2. На нем: logstash, elasticsearch (with watcher plagin), kibana, membrane-service-proxy (вместо elastic Shield).
Принцип работы (beats+ELK).
FileBeat выступает в роли агента, при появлении новых данных (причем склеивает их используя multiline) отправляет пакет в logstash. Logstash преобразовывает данные в JSON и отправляет в elasticsearch. Kibana выступает в роли вьюшки. Membrane-service-proxy используется для авторизации к elasticsearch и Kibana.
При реализации этой схемы столкнулся со следующими проблемами:
- Лишний символ (0xEF 0xBB 0xBF)
Логи ТЖ (*.log) записываются в кодировке UTF-8. Как следствие в начало каждого файла добавляется ‘п»ї’ (0xEF 0xBB 0xBF). Подробнее W3 UTF-8.
В filebeat.yml я указал encoding: utf-8, но проблема осталась.
Как следствие я теряю одно событие в каждом новом файле лога.
Пример того что filebeat отправляет в logstash:
{ "@timestamp": "2016-05-12T12:06:53.593Z", "beat": { "hostname": " 1CAPP-07", "name": "1CAPP-07" }, "count": 1, "fields": null, "input_type": "log", "message": "**?**06:45.0409-229386,SDBL,3,process=rphost,p:processName=PP ,t:clientID=919,t:applicationName=1CV8,t:computerName=TERM4,t:connectID=9603, SessionID=6119,Usr=...,Trans=0,Func=Transaction,Func=CommitTransa ction", "offset": 5691, "source": "T:\\tehjourn\\rphost_8876\\16051215.log", "type": "tj1s" }
- Преобразование даты события в UTC
Получая данные в logstash и разбирая их я получаю две даты: @timestamp (дата и время обработки логов из beats) и timestamp (дата события из ТЖ – собирается из 16051215.log и ?06:45.0409).
Обеда даты имеют формат "YYYY-MM-dd HH:mm:ss.SSS Z (mutate {add_field => { “timestamp” => “%{year}-%{month}-%{day}T%{hour}:%{minute}:%{second}Z” }})
@timestamp – если я правильно понимаю в UTC, а timestamp в локальном формате.
Как timestamp перевести в UTC?
Помогите пожалуйста решить эти проблемы.
Этот “лишний символ” - byte offset mark. пересохраните (рядом) в файл без BOM, или вырежьте его кодом
Я понимаю.
пересохраните (рядом) в файл без BOM
в контексте моей задачи - не вариант.
вырежьте его кодом
в filebeat это можно сделать? или наверное только в logstash…
Сам спросил и по классике жанра сам отвечу.
п.1
не нашел простого пути избавиться от BOM средствами filebeat, отрезал его logstash’ом.
mutate {gsub => ["message", "^[\W]{1,}", ""]}
п.2
(mutate {add_field => { "timestamp" => "%{year}-%{month}-%{day}T%{hour}:%{minute}:%{second}Z"}})
не внимательно ознакомился с ISO 8601.
вместо Z (признак времени по UTC) необходимо указать часовой пояс +03:00 ("%{year}-%{month}-%{day}T%{hour}:%{minute}:%{second}+03:00")
Вместо часового пояса +03:00 можно так же указать Europe/Moscow. подробнее тут
Провел свой микро тест.
10 раз по 10 000 строк. 4 метода. Результат в табличке. Победителем оказался ЗаписьТекста
1 Симпатия
Всем привет!
Помогите пожалуйста разобраться в ошибке.
Я использую PaketBeat (Version: 1.2.3) для анализа трафика и записи в elasticsearch.
Регулярно получаю следующую ошибку:
2016/08/08 15:29:09.853618 decoder.go:97: INFO packet decode failed with: Invali d (too small) IP length (0 < 20) 2016/08/08 15:29:12.853618 http.go:421: WARN Response from unknown transaction. Ingoring.
Пакеты c подобной ошибкой PaketBeat соответственно не разбирает.
PaketBeat запускаю с ключами ..\packetbeat.exe -e -dump c:\temp\trace2.pcap.
В trace2.pcap (https://drive.google.com/open?id=0B_459K_hkeaRb2VhNjhZOVhsWEE)
визуально проблем нет, все отображается корректно.
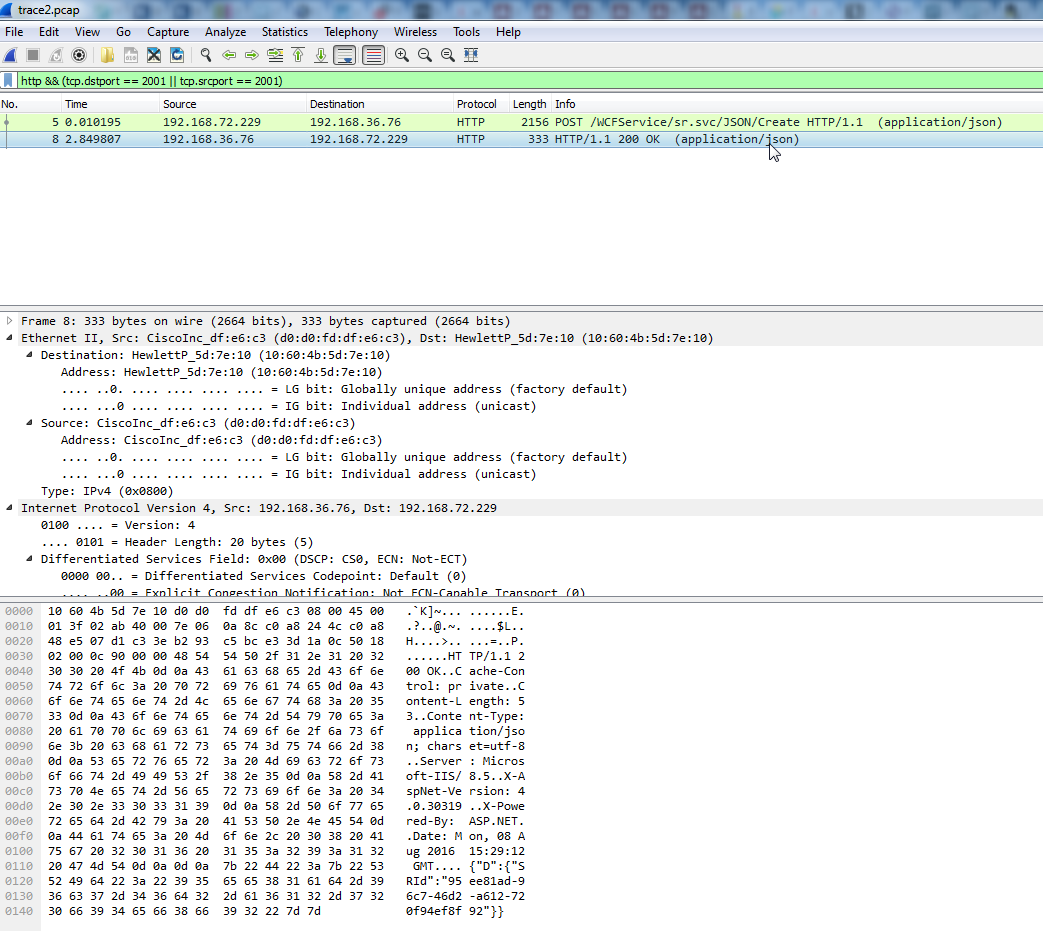
packetbeat.yml:
`
############################# Sniffer #########################################
interfaces:
device: 0
############################# Protocols #######################################
protocols:
http:
ports: [2001]
send_all_headers: true
include_body_for: ["application/json","text/html"]
send_request: true
send_response: true
transaction_timeout: 2s
############################# Output ##########################################
output:
console:
pretty: true
`
Подскажите пожалуйста в чем может быть проблема и как можно ее решить?