
Я что-то пропустил ? Откуда инфа ?
BigData LogManager для 1С
Я имел ввиду, что они сами не рекомендуют использовать такой формат ЖР в продуктиве на больших базах.
У себя именно кодом сейчас и выгружаем. Плюс регулярно отрезаем уже выгруженные куски журнала - в нашем варианте это удобно отслеживать.
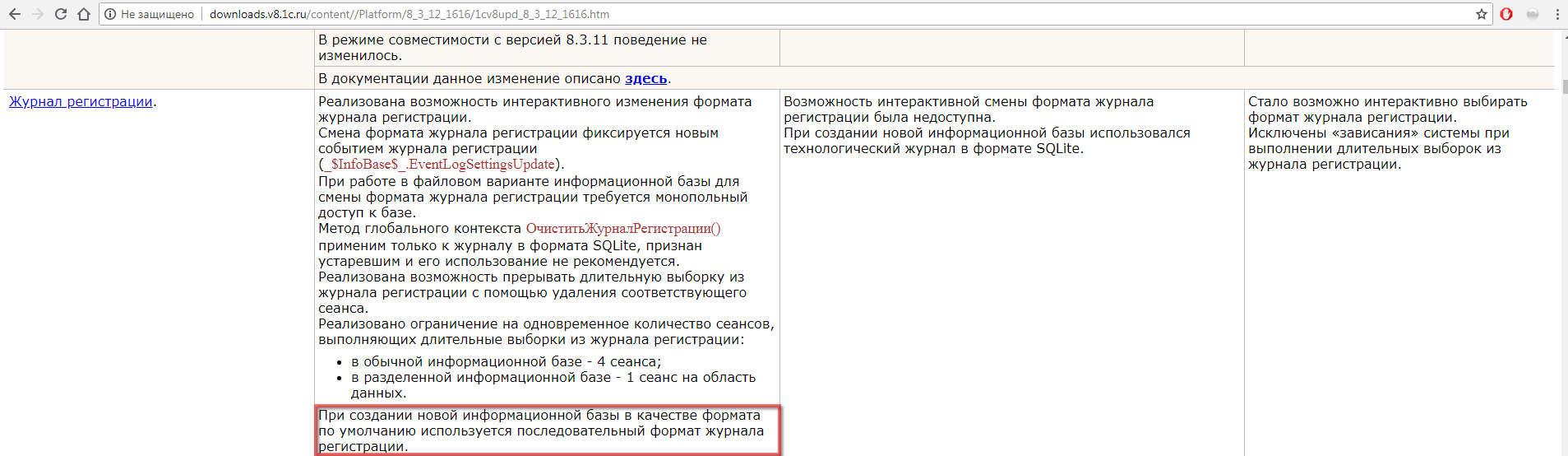
Это для актуальных версий платформы ) для тех, кто ещё не слез со старых, остаются боль, страдания и lgd.
Дык всегда можно переключиться в старый формат. В чем проблема?
1 Симпатия
Старый тупит, если б не тупил - данный топик не имел бы смысла
В каком плане тупит? Старый вариант же как раз лучше работает по скорости записи.
При чтении из него и поиске
Новый тупит не меньше, при достаточном объеме.
Вот поэтому и отрезаем выгруженные куски к чертям - они всё равно уже в ES.
Добрый день!
Дошли руки до сбора логов, поставили graylog.
Решил сначала собрать записи ЖР из текстовых файлов через filebeat в graylog.
Пока смотрятся только файлы данных *.lgp с такими настройками в yml
multiline.pattern: '^{\d{14}.+$' multiline.negate: true
События прилетают, но ни пользователя, ни метаданных, ни других полезных вещей не видно.
Как лучше сделать загрузку с определением значений массивов в 1Cv8.lgf? Pipeline видимо надо какой-то использовать, как его описать?
Может кто-нибудь поделиться наработками?
Спасибо
А там поддерживаются человекочитаемые имена метаданных и пользователи?
Да, поддерживает вроде, вот его статья на ИС https://infostart.ru/public/182820/
Формат логов в старом формате описан, например, тут: https://infostart.ru/public/182061/
по сути эта его программа разбирает логи и кладет в mssql.
а мне хотелось бы реализовать разбор ми отправку на filebeat без дополнительных шлюзов.
мне очень понравилась идея “Старый журнал + filebeat -> es”
Тут надо свой beat написать. Для разработки битов есть шаблон.
Я даже в какой-то момент начал эту задачу, но оно пока настолько концепт, что не публикую )
Она не обязательно кладет в MSSQL, она умеет сразу в эластик отправлять
Я не помню указывали или нет - пусть будет тут
Только это ТЖ, но пусть будет тут
У меня такая схема вышла: 1С ЖР => файлы, разбитые по дням => logstash => elasticsearch
Logstash’ем собираю ЖР из файлов с логами(lgp), фильтрую и загружаю в Elasticsearch, поиск и графики через Kibana. Из файла lgf составляю маппинг и отдаю его логсташу, чтобы была возможность видеть не только непонятные IDшники, но ещё и “human-readable” данные.
Сырых данных ЖР > 1ТБ. В эластике занимают места процентов на 20% меньше, благодаря сжатию.
Могу поделиться наработками, если кому интересно.
