Добрый день, коллеги.
Прошу совета, как у более опытных.
Столкнулся с тем, что не могу понять как правильно разделять фича-файлы. проблема скорее в терминах и понятиях.
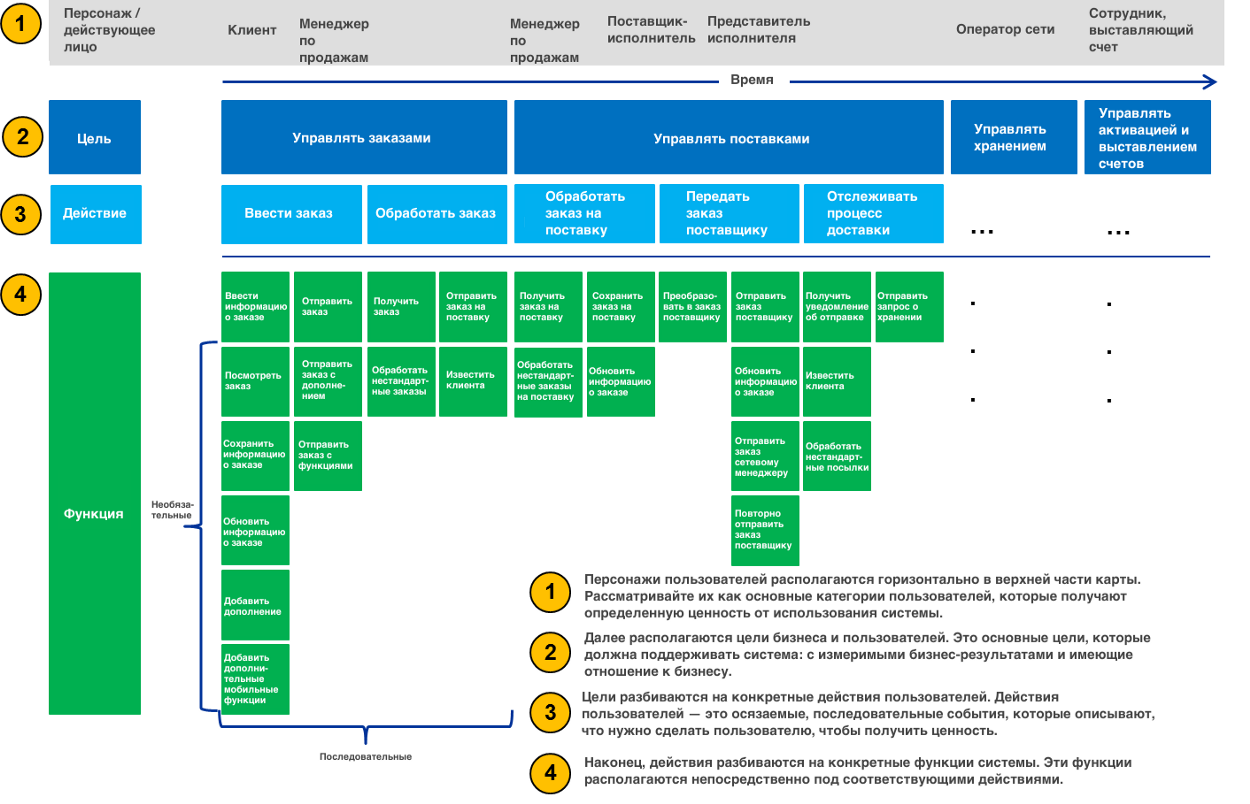
Feature - возможность, функционал, законченный.
feature-файл - содержит в себе набор сценариев с тестами конкретно этой фичи продукта.
Пока все понятно.
А как быть с тем, когда тестируемая фича пересекается с другой фичей?
Например, фича - настраиваемый нумератор объекта (справочника или документа)
Кроме самого объекта “Нумератор” разработка этой фичи затрагивает другой объект - справочник ОбъектыМетаданных, который по сути является агрегатором настроек для конкретного бъекта метаданных. В т.ч. и настройка нумерации его с помощью разрабатываемого нумератора.
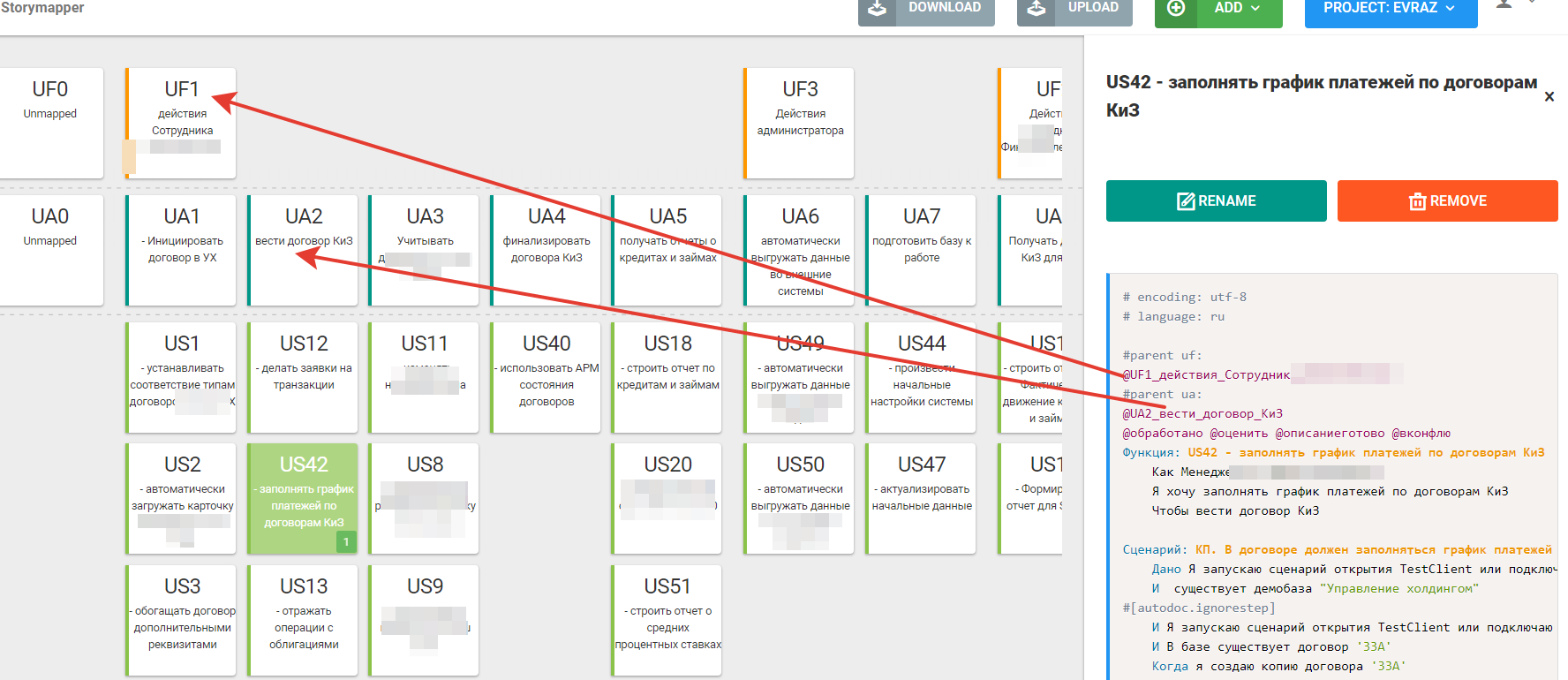
Сам справочник “объекты метаданных” тоже фича продукта и у него тоже есть свой фича файл со сценариями.
Таким образом технически разрабатывая новую фичу я добавляю в существующую фичу доп функционал.
Как правильно будет распределить сценарии по фича файлам.?
Если я все сценарии связанные с новой фичей логически запихну в один фича-файл “Нумераторы”, то как я потом прогоню регресс только по фиче “объекты метаданных” ?
Если я раскидаю сценарии по новой фиче согласно логике разработки - часть в фичу по нумератору, часть добавлю в фича -файл по объекту метаданных, тогда получится запускать регресс изолированно по объекту метаданных, но прогон тестов по нумератору будет не полным.
Возможно ответ в тегах и тогда можно делать фичафайлы мельче и тегами их метить, тогда один фича файл с пересекающимися сценариями будет гоняться в регрессе в обоих случаях, когда я буду проверять нумераторы и объекты метаданных по ситуации.
Но в этом случае нарушается представление о том что такое feature.
Подскажите, как вы делаете в таких ситуациях?