Возможно холиварный вопрос, но интересно мнение сообщества - кто и как думает:
Формирование тестового окружения через pipeline можно воспользоваться 2-мя вариантами:
Файловая база и серверная.
- файловая база
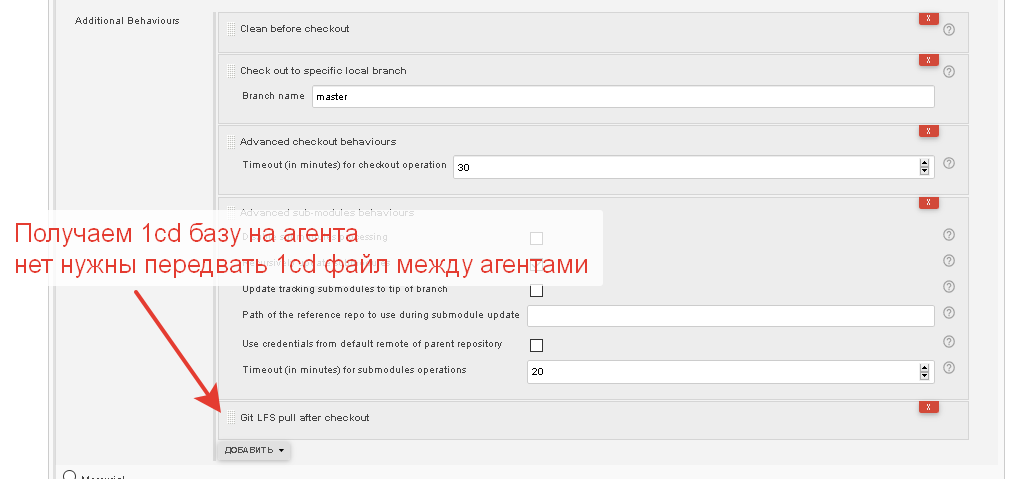
Если использовать файловую базу, то нам необходимо предварительно загрузить в нее шаблонный dt файл, затем уже накатить исходники из хранилища. Без шаблонного dt, мы упираемся в проблему начальной инициализации БД и зачастую не возможности корректно отработать дымовым и функциональным тестам.
Плюсы:
- Окружение создается каждый раз новое - все везем из репо
- В некоторых случаях экономия серверной лицензии
Минусы - Загрузка шаблонного dt в файловую базу, для больших конфигураций может занимать очень много времени
- Серверный вариант
База заранее создается для проведения тестов, и возможно ежедневное/по требованию восстановление из шаблонного бейкапа средствами sql.
Плюсы:
- Для больших баз этот вариант быстрее
- ?
Минусы: - наличие серверной лицензия на 1С
- окружение не формируется сборочной линией
И тот и другой вариант в принципе допустим и используется. Какой по вашему мнению правильный и в каком случае Вы стали бы его использовать?